excel怎么统计分隔符的字符串
Q:某些情况下,我们可能要统计带有分隔符的字符串中不重复的子字符串数。如下所示,我想知道单元格A1中不重复的数字有几个,应该怎么编写公式?
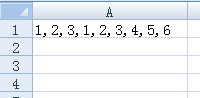
A:下面的数组公式可以完成单元格A1的字符串不重复值的统计:
=SUM(N(MATCH(TRIm(MId(SUBSTITUTE(A1,”,”,REPT(“”,999)),ROW(INDIRECT(“1:” &LEN(A1)-LEN(SUBSTITUTE(A1,”,”,””))+1))*999-998,999)),TRIm(MId(SUBSTITUTE(A1,”,”,REPT(“”,999)),ROW(INDIRECT(“1:” &LEN(A1)-LEN(SUBSTITUTE(A1,”,”,””))+1))*999-998,999)), )=ROW(INDIRECT(“1:”& LEN(A1)-LEN(SUBSTITUTE(A1,”,”,””))+1))))
结果为6。注意,公式输入完成后要按下Ctrl+Shift+Enter组合键。
公式解析
这么长的公式,一看到可能被吓着了,让我们来看看这个复杂的公式是怎么得来的。
上面的公式可以简化为:
=SUM(N(MATCH(单元格中的子字符串组成的数组, 单元格中的子字符串组成的数组, )=连续数字组成的数组))
其中,生成单元格中的子字符串组成的数组的公式:
TRIm(MId(SUBSTITUTE(A1,”,”,REPT(“”,999)),ROW(INDIRECT(“1:” &LEN(A1)-LEN(SUBSTITUTE(A1,”,”,””))+1))*999-998,999))
ROW(INDIRECT(“1:”& LEN(A1)-LEN(SUBSTITUTE(A1,”,”,””))+1))获得从1至子字符串个数的连续数字。本例中,单元格中的子字符串组成的数组为:
{“1″;”2″;”3″;”1″;”2″;”3″;”4″;”5″;”6”}
上述数组作为MATCH函数的参数,查找每个子字符串在上面数组中出现的位置,得到下面的数组:
{1;2;3;1;2;3;7;8;9}
公式中的:
ROW(INDIRECT(“1:”& LEN(A1)-LEN(SUBSTITUTE(A1,”,”,””))+1))
生成由连续的数字组成的数组:
{1;2;3;4;5;6;7;8;9}
上面生成的两个数组进行比较:
{1;2;3;1;2;3;7;8;9}={1;2;3;4;5;6;7;8;9}
得到由布尔值组成的数组:
{TRUE;TRUE;TRUE;FALSE;FALSE;FALSE;TRUE;TRUE;TRUE}
其中的TRUE表明是不重复的值,FALSE表明值出现的重复。因为不重复值出现的位置应该与其在子字符串中的位置一致,也就是说比较的结果为TRUE;如果位置不一致,则前面已经出现过该子字符串,即为重复值,比较的结果为FALSE。
N函数将上述布尔值数组转换成由和1组成的数组:
{1;1;1; ; ; ;1;1;1}
数组中元素之和即为不重复的值的个数。
图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!
内容声明:本文中引用的各种信息及资料(包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主体(包括但不限于公司、媒体、协会等机构)的官方网站或公开发表的信息。部分内容参考包括:(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供参考使用,不准确地方联系删除处理!本站为非盈利性质站点,发布内容不收取任何费用也不接任何广告!
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理,本文部分文字与图片资源来自于网络,部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理!的,若有来源标注错误或侵犯了您的合法权益,请立即通知我们,情况属实,我们会第一时间予以删除,并同时向您表示歉意,谢谢!
