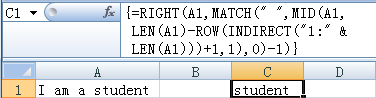
使用公式来获取字符串的最后一个单词。如下图所示,提取列A单元格中字符串的最后一个单词,将其放置到列C相应的单元格中。

先不看下面的内容,自已试一试。
公式思路
首先查找字符串中空格最后一次出现的位置,然后从该位置起提取字符串结尾部分的单词。
公式解析
在单元格C1中输入数组公式:
=RIGHt(A1,MATCH(“”,MId(A1,LEN(A1)-ROW(INDIRECT(“1:” & LEN(A1)))+1,1),0)-1)
向下拖动至单元格C2,结果如下图所示。
为方便对数组公式的理解,先以单元格A1中的字符串为例,一步一步导出适用的公式。
第1步:如下图所示,由于列A中的字符串共14个字符,因此在B列中选取单元格区域B1:B14,输入数组公式:
=ROW(INDIRECT(“1:” & LEN(A1)))
得到一个包含从1至14的连续数字的数组并将其放置在单元格区域中。

第2步:选择单元格区域C1:C14,输入数组公式:
=LEN(A1)-B1:B14+1
得到与列B中数字逆序的数组并放置在单元格区域中。

第3步:选择单元格区域D1:D14,输入数组公式:
=MId(A1,C1:C14,1)
使用MID函数按C1:C14中的数字从A1中的最后一个字符开始提取字符,并放置在单元格区域中。
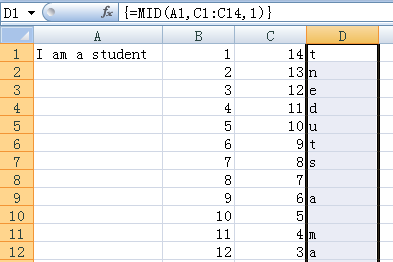
第4步:在单元格E1中输入公式:
=MATCH(” “,D1:D14,0)
使用MATCH函数查找空格出现的位置。因为已经将A1中的字符串逆序排列,所以该位置就是原字符串中最后一个空格的位置。

第5步:在单元格F1中输入公式:
=LEN(A1)-E1+1
得到单元格A1字符串中最后一个空格的位置。

第6步:使用下面的公式:
=LEN(A1)-(LEN(A1)-E1+1)
得出字符串中最后一个单词的字符数,即字符串总的字符数减去最后一个空格在字符串中的位置的结果。
第7步:使用下面的公式:
=RIGHt(A1,LEN(A1)-(LEN(A1)-E1+1))
获取字符串中最后一个单词。
将最后得到的公式依次使用前一步得到的公式替换,最终得到只包含A1的公式,即本文开头的数组公式。
小结
本文提供了从字符串的结尾开始查找指定字符第一次出现的位置的一种方法。
在第4步中,其实已经得出了逆序排列时最后一个空格的位置,减去1即为最后一个单词的字符数。然后,将其直接作为RIGHT函数的参数,即可得到结果。
一步一步得出中间结果,然后再逐步替换得到最终的公式,这是编写大公式的一个通用方法。
图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!
内容声明:本文中引用的各种信息及资料(包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主体(包括但不限于公司、媒体、协会等机构)的官方网站或公开发表的信息。部分内容参考包括:(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供参考使用,不准确地方联系删除处理!本站为非盈利性质站点,发布内容不收取任何费用也不接任何广告!
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理,本文部分文字与图片资源来自于网络,部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理!的,若有来源标注错误或侵犯了您的合法权益,请立即通知我们,情况属实,我们会第一时间予以删除,并同时向您表示歉意,谢谢!
